
Dans le monde actuel axé sur les données, les entreprises s’appuient de plus en plus sur les grands modèles linguistiques (LLM) pour créer de nouvelles opportunités en matière d’automatisation, de prise de décision et d’engagement des clients. Toutefois, pour les entreprises des secteurs réglementés ou celles qui accordent la priorité à la confidentialité des données, le déploiement de LLM sur le cloud n’est pas toujours la meilleure solution. Le déploiement de LLM sur site est une alternative sécurisée, personnalisable et rentable. Ce guide explore tout ce que vous devez savoir sur l’exécution des LLM localement, depuis la compréhension des principes de base jusqu’à la résolution des problèmes de déploiement et l’identification des meilleurs cas d’utilisation.
Qu’est-ce qu’un LLM sur site ?
Un LLM sur site fait référence au déploiement de grands modèles linguistiques sur l’infrastructure locale d’une entreprise plutôt que de s’appuyer sur des services basés sur le cloud. Cette approche permet aux entreprises de contrôler totalement leurs données, leur infrastructure et la personnalisation des modèles, ce qui en fait la solution idéale pour les entreprises ayant des exigences strictes en matière de conformité ou celles qui traitent des informations sensibles.

Comprendre les grands modèles linguistiques (LLM)
Les grands modèles de langage (LLM) sont des systèmes d’IA avancés conçus pour comprendre et générer des textes de type humain. Construits sur des architectures d’apprentissage profond, ces modèles sont entraînés sur de vastes ensembles de données, ce qui leur permet d’effectuer des tâches telles que le résumé de texte, la traduction et la génération de code. Parmi les exemples les plus courants, citons GPT-4, Llama-3, DeepSeek, Claude, Mistral, Qwen-2.5 ou Gemini. Leurs applications couvrent de nombreux secteurs, des chatbots d’assistance à la clientèle à la gestion des connaissances d’entreprise.
Déploiement sur site ou dans le nuage : Principales différences
| Aspect | LLM sur site | LLM basé sur l’informatique dématérialisée |
| Sécurité des données | Élevé ; les données restent au sein de l’organisation | Dépend de la sécurité du fournisseur de services en nuage |
| L’infrastructure | Nécessite du matériel local (GPU, serveurs) | Aucun investissement en matériel n’est nécessaire |
| Coût | Des coûts initiaux plus élevés, des coûts à long terme plus faibles | Modèle de paiement à l’utilisation |
| Évolutivité | Limité par les ressources locales | Hautement modulable |
| Personnalisation | Contrôle total de la mise au point du modèle | Limité par les offres des fournisseurs de services en nuage |
Le déploiement sur site est particulièrement avantageux pour les entreprises qui privilégient la confidentialité des données, la rentabilité et la personnalisation.
Pourquoi déployer un LLM sur site ? Principaux avantages
Le déploiement d’un LLM sur site offre plusieurs avantages convaincants, en particulier pour les organisations ayant des besoins spécifiques en matière de sécurité, de contrôle et de performance.
Sécurité des données et conformité
Pour des secteurs comme la santé, la finance et le gouvernement, la sécurité des données n’est pas négociable. Les LLM sur site garantissent que les informations sensibles ne quittent jamais l’infrastructure de l’organisation, aidant ainsi les entreprises à se conformer à des réglementations telles que GDPR, HIPAA et CCPA. Cela est particulièrement important lorsque vous traitez des données personnelles, des dossiers médicaux ou des documents financiers.
Bon à savoir: Le déploiement sur site réduit également le risque de violation des données de tiers, qui est devenu de plus en plus courant dans les environnements en nuage.
Conseil d’expert – La sécurité d’entreprise à grande échelle
Chez Kairntech, nous combinons le déploiement de LLM sur site avec un contrôle d’accès précis, une authentification unique (SSO) et une auditabilité complète. Cela garantit la traçabilité et la sécurité de tous les flux de travail alimentés par l’IA, quel que soit votre cadre de conformité (GDPR, HIPAA, ISO/IEC 27001).
Contrôle total de l’infrastructure et de la personnalisation
Avec un LLM sur site, les entreprises ont un contrôle total sur leur infrastructure. Cela permet d’affiner le modèle pour répondre à des besoins spécifiques, qu’il s’agisse d’optimiser pour une langue particulière, un jargon industriel ou un cas d’utilisation. Par exemple, un cabinet d’avocats peut affiner un LLM pour mieux respecter le format et le ton du texte de sortie.
Rentabilité pour les charges de travail élevées
Si les coûts d’installation initiaux des LLM sur site peuvent être élevés, ils s’avèrent souvent plus rentables à long terme, en particulier pour les entreprises qui ont des besoins élevés en matière de traitement de l’IA. En éliminant les frais récurrents d’utilisation du cloud, les entreprises peuvent réaliser d’importantes économies au fil du temps.
Une latence plus faible et un traitement plus rapide
L’exécution d’un LLM sur une infrastructure locale réduit la dépendance à l’égard des réseaux externes, ce qui se traduit par une latence plus faible et des temps de traitement plus rapides. Ceci est crucial pour les applications en temps réel comme les chatbots où les délais peuvent avoir un impact sur l’expérience de l’utilisateur ou la prise de décision. Pour les éditeurs, cela peut être vital lorsqu’il s’agit d’analyser d’énormes quantités de documents (archives) afin d’accélérer le processus (résumé de texte par exemple).
Comment déployer un LLM sur site : Guide étape par étape
Le déploiement d’un LLM sur site nécessite une planification et une exécution minutieuses. Voici un guide étape par étape pour vous aider à naviguer dans le processus.
Choisir le bon modèle de LLM
La première étape consiste à sélectionner le LLM adapté à vos besoins. Les modèles open-source comme Llama3, Nemotron-70B, Mistral, Qwen2.5, Phi-4 sont des choix populaires pour un déploiement sur site en raison de leur flexibilité et du soutien de la communauté. Prenez en compte des facteurs tels que la taille du modèle, la taille du contexte et les cas d’utilisation spécifiques (réponse aux questions, chatbot RAG, résumé de texte, génération de mots-clés…) au moment de prendre votre décision.
Exigences en matière de matériel et d’infrastructure
Les LLM sur site nécessitent un matériel robuste pour répondre à leurs besoins de calcul. Les principaux composants sont les suivants :
- GPU: Les GPU haute performance de NVIDIA ou AMD sont essentiels pour la formation et l’inférence.
- MÉMOIRE VIVE: Une mémoire d’au moins 64 Go est recommandée pour la plupart des grands modèles.
- Stockage: Des disques SSD de grande capacité sont nécessaires pour stocker les ensembles de données et les poids des modèles.
Liste de contrôle – Êtes-vous prêt pour l’infrastructure ?
Avant de déployer votre LLM sur site, vérifiez les points suivants (les exigences en matière d’infrastructure dépendent de la taille et du nombre de LLM requis) :
- ✅ Au moins 1 ou 2 GPU haute performance
- ✅ 64-128 Go de RAM minimum
- stockage SSD d’une capacité d’au moins 1 To
- Systèmes d’alimentation et de refroidissement redondants
- ✅ Réseau interne à haut débit (10 Gbps+)
- ✅ Capacités DevOps ou MLOps internes
Conseil de pro : Kairntech propose un modèle d’infrastructure conçu pour les déploiements sur site à l’échelle de l’entreprise.
Logiciels et cadres de déploiement
Pour déployer votre LLM, vous aurez besoin des bons outils logiciels. Les frameworks tels que TensorFlow, PyTorch et Hugging Face Transformers sont largement utilisés pour l’apprentissage et l’inférence des modèles. Pour des performances optimisées, envisagez des moteurs d’inférence comme vLLM ou SGLang.
Installation et configuration du LLM
Une fois que votre matériel et vos logiciels sont en place, les étapes suivantes consistent à installer, configurer et faire fonctionner le LLM. Cela implique généralement :
- la sélection et le téléchargement d’un programme d’éducation et de formation tout au long de la vie spécifique,
- le réglage de certains paramètres du LLM,
- la mise en place du LLM,
- en envoyant une demande au LLM.
Par exemple, déployer et envoyer une requête à Llama 3 en utilisant la boîte à outils VLLM :
- sur la machine pour le service LLM, « vllm serve meta-llama/Llama-3.3-70B-Instruct »,
- à partir d’une machine cliente,
« curl http://localhost:8000/v1/chat/completions \N-
-H « Content-Type : application/json » \N-
-d ‘{
« model » : « meta-llama/Llama-3.3-70B-Instruct »,
« messages » : [
{« role » : « system », « content » : « You are a helpful assistant. »},
{« role » : « utilisateur », « contenu » : « Qui a gagné la série mondiale en 2020 ? »}
],
« temperature » : 0,1
« max_tokens » : 16000
}’ « .
Ajustement et personnalisation
Le réglage fin vous permet d’adapter un LLM pré-entraîné à vos besoins spécifiques. Cela implique d’entraîner le modèle sur un ensemble de données plus petit et spécifique au domaine. Par exemple, une entreprise de médias proposant un chatbot de vente et de marketing pourrait affiner un LLM pour mieux générer une réponse sous la forme d’un e-mail ou d’un argumentaire de vente, ou même d’un post Linkedin.
Cas d’utilisation réel – L’assistant juridique en action
Un cabinet d’avocats a utilisé l’assistant sur site de Kairntech pour affiner un LLM sur la jurisprudence interne et les modèles de contrats. L’assistant rédige désormais des mémos juridiques en quelques secondes, sans qu’aucune donnée ne quitte le réseau.
Contrôle et optimisation des performances
Après le déploiement, il est crucial de surveiller les performances du LLM. Utilisez des outils tels que Prometheus ou Grafana pour suivre les mesures telles que le temps d’inférence et l’utilisation des ressources. Optimisez régulièrement le modèle pour vous assurer qu’il reste efficace.

Défis du déploiement du LLM sur site (et comment les surmonter)
Si les LLM sur site présentent de nombreux avantages, ils s’accompagnent également de défis que les entreprises doivent relever.
Coûts d’infrastructure et de maintenance élevés
La mise en place et la maintenance d’un LLM sur site peuvent être coûteuses. Pour réduire les coûts, envisagez d’optimiser l’utilisation des ressources et d’exploiter du matériel optimisé pour l’IA, comme les GPU A100 de NVIDIA.
Complexité de la mise en place et de la gestion
Le déploiement d’un LLM nécessite une expertise technique importante. Simplifiez le processus en utilisant des outils tels que Kubernetes pour l’orchestration des conteneurs et les plateformes MLOps pour la gestion du cycle de vie.
Mises à jour et versions du modèle
Maintenir votre LLM à jour tout en conservant la compatibilité avec les applications existantes peut s’avérer difficile. Mettez en œuvre une solide stratégie de gestion des versions et automatisez les mises à jour dans la mesure du possible.
Erreur fréquente – Sous-estimation des besoins de mise à jour du modèle
De nombreuses organisations déploient un LLM une seule fois et oublient la version du modèle. Cela peut conduire à des réponses obsolètes et à une augmentation des hallucinations.
Notre conseil: Mettez en place un pipeline MLOps avec une validation par étapes, et planifiez des évaluations trimestrielles du modèle pour assurer la continuité des performances.
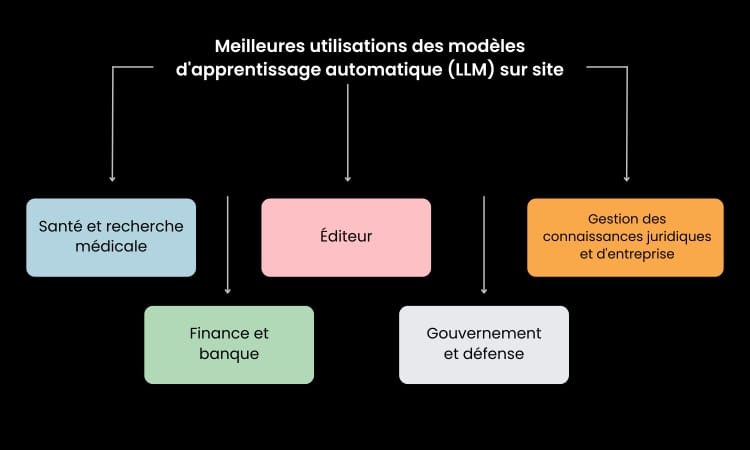
Les meilleurs cas d’utilisation pour les LLM sur site
Les LLM sur site sont particulièrement bien adaptés aux industries qui ont des exigences strictes en matière de confidentialité et de sécurité des données.
Soins de santé et recherche médicale
Dans le secteur de la santé, les LLM sur site peuvent analyser les données des patients tout en garantissant la conformité avec la loi HIPAA et d’autres réglementations. Ils sont également très utiles pour accélérer la recherche médicale en traitant de grandes quantités de littérature scientifique.
Finance et banque
Les institutions financières utilisent les LLM sur site pour la détection des fraudes, l’analyse des risques et la conformité réglementaire. En conservant les données financières sensibles sur site, elles peuvent éviter les risques associés au stockage en nuage.
Éditeurs
Les éditeurs font appel à des LLM locaux pour garantir la non-divulgation des contenus vendus sous copyright. Dans certains cas, le contenu de tiers peut être revendu et fait donc l’objet d’un partage des revenus avec les éditeurs partenaires.
Gouvernement et défense
Les gouvernements et les organisations de défense s’appuient sur des LLM sur site pour des applications d’IA confidentielles, telles que l’analyse de renseignements et la communication sécurisée.
Gestion des connaissances juridiques et d’entreprise
Les cabinets d’avocats et les entreprises utilisent des LLM sur site pour gérer le traitement de documents à grande échelle, en veillant à ce que les informations juridiques et commerciales sensibles restent sécurisées.
Avantage clé – Maîtrise du domaine
Les LLM sur site permettent une personnalisation approfondie pour les industries de niche.
Avec Kairntech, les experts du domaine peuvent affiner les pipelines pour des tâches hautement spécialisées (par exemple, l’analyse du langage réglementaire, l’exploration de la littérature scientifique) sans écrire de code.
Outils et plates-formes LLM sur site
Plusieurs outils et plateformes facilitent le déploiement de LLM sur site.
LLM à code source ouvert adaptés à une utilisation sur site
Les modèles open-source les plus populaires sont Llama-3, Qwen-2.5, Nemotron-72B, DeepSeek… Ces modèles offrent une grande flexibilité et sont soutenus par des communautés de développeurs actives.
MLOps et outils de déploiement
Des outils tels que Hugging Face Transformers, NVIDIA Triton Inference Server et Kubernetes simplifient le déploiement et la gestion des LLM sur site.
Fournisseurs de matériel optimisé pour l’IA
Les principaux fournisseurs de matériel tels que NVIDIA, AMD et Intel proposent des GPU et des accélérateurs d’IA conçus pour un déploiement LLM à haute performance.
Tendances futures en matière de déploiement de LLM sur site
L’avenir des LLM sur site est façonné par les technologies émergentes et l’évolution des besoins des entreprises.
Modèles d’IA périphérique et d’IA décentralisée
L’Edge AI permet un traitement sur l’appareil, réduisant la latence et améliorant la confidentialité. Cette tendance est particulièrement pertinente pour les industries telles que les soins de santé et la fabrication.
Progrès dans l’efficacité matérielle de l’IA
Les nouveaux développements en matière de puces d’IA et de modèles d’inférence à faible consommation rendent le déploiement sur site plus accessible et plus rentable.
Solutions hybrides de cloud et d’IA sur site
Les solutions hybrides combinent l’évolutivité de l’informatique dématérialisée et la sécurité d’un déploiement sur site, offrant ainsi aux entreprises le meilleur des deux mondes.

Mythe ou réalité – La vérité sur l’IA sur site
| Mythe | Réalité |
| L’IA sur site est dépassée par rapport à l’informatique dématérialisée | Les LLM modernes à code source ouvert tels que Llama-3, Mistral et DeepSeek offrent des performances de pointe et peuvent être déployés sur site. |
| Vous avez besoin d’une équipe d’IA complète pour le faire fonctionner | Avec des plateformes à code bas comme Kairntech, les experts du domaine peuvent exploiter, maintenir et faire évoluer eux-mêmes les assistants. |
| Les LLM sur site ne sont pas évolutifs | Lorsqu’elles sont optimisées avec Kubernetes et des moteurs d’inférence, elles s’adaptent horizontalement à l’infrastructure de l’entreprise |
Conclusion : Le déploiement d’une LLM sur site est-il adapté à votre entreprise ?
Le déploiement d’un LLM sur site offre un contrôle, une sécurité et une rentabilité inégalés pour les entreprises ayant des besoins spécifiques. Cependant, il nécessite un investissement important en termes d’infrastructure et d’expertise. Avant de prendre une décision, évaluez les exigences de votre organisation en matière de confidentialité des données, votre budget et vos capacités techniques. Avec la bonne approche, les LLM sur site peuvent libérer un potentiel de transformation pour votre entreprise.





