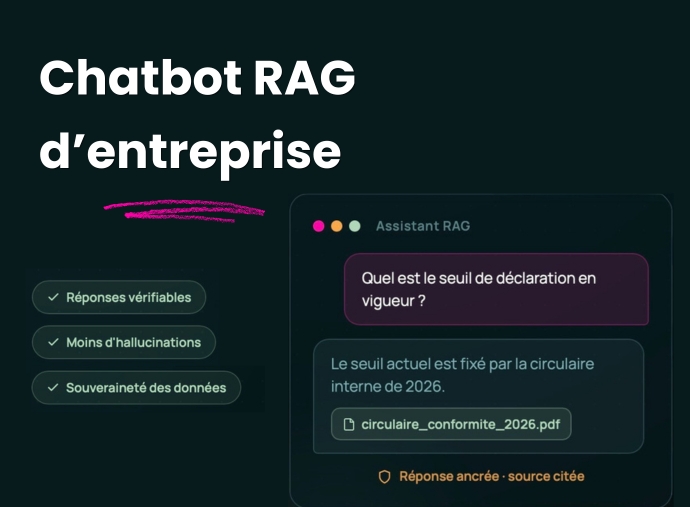
Dans le paysage en constante évolution du traitement du langage naturel (NLP), l’extraction joue un rôle crucial dans la structuration de l’information textuelle. En identifiant les entités clés, les faits et les éléments structurés dans un document ou dans des ensembles de données, cette technique alimente les graphes de connaissances, les systèmes de recherche intelligents et la prise de décision automatisée. Des approches basées sur des règles aux modèles d’apprentissage profond, l’extraction a évolué vers un pipeline sophistiqué qui améliore l’analyse de texte pilotée par l’IA. Ce guide explore ses techniques de base, ses applications pratiques et les outils les plus efficaces pour vous aider à l’intégrer dans vos projets de NLP.
Introduction à l’extraction dans le cadre du NLP
Qu’est-ce que l’extraction NLP?
L’extraction NLP est une tâche fondamentale du NLP, conçue pour identifier et catégoriser des informations significatives dans une phrase ou un document. À partir d’un texte d’entrée, un modèle entraîné analyse la représentation des mots et extrait des données structurées à différents niveaux de granularité.
Par exemple, dans la phrase « Albert Einstein a développé la théorie de la relativité », un pipeline d’extraction identifie « Albert Einstein » comme une entité, « théorie de la relativité » comme une autre entité, et capture le sens contextuel de la phrase. Ces informations structurées sont ensuite stockées dans un graphe de connaissances, ce qui facilite leur extraction, leur analyse et leur utilisation dans différentes applications NLP.
À la base, l’extraction NLP améliore la façon dont les informations textuelles sont traitées, transformant les données non structurées en représentations structurées qui alimentent les systèmes intelligents.
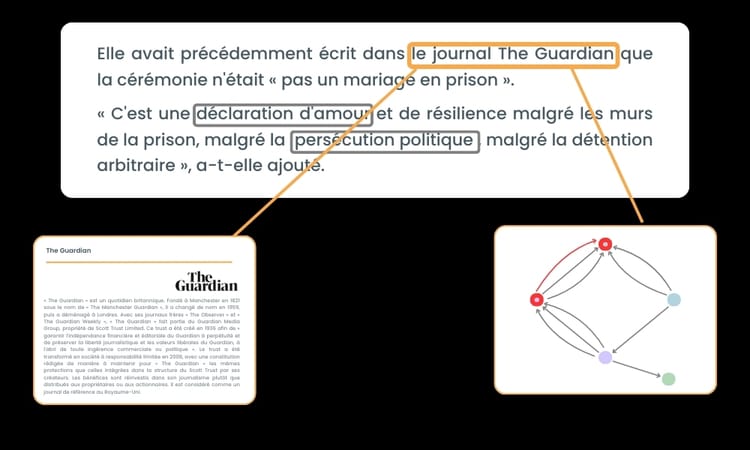
Importance de l’extraction NLP
La compréhension et l’extraction d’informations clés à partir de textes ouvrent un large éventail de possibilités pour l’analyse de textes et la recherche d’informations. Ce processus est essentiel dans de nombreux domaines, de la construction de graphes de connaissances pour les assistants pilotés par l’IA à l’automatisation des tâches de classification et de prédiction des documents.
Dans un contexte professionnel, l’extraction NLP améliore la prise de décision en organisant les documents et en faisant ressortir les informations pertinentes. Par exemple, les institutions financières l’utilisent pour extraire les mentions d’entreprises, les risques réglementaires et les tendances du marché. Dans le domaine de la santé, elle permet d’extraire des points de données critiques de textes médicaux, tels que les conditions, les traitements et les symptômes, afin d’alimenter la recherche avancée et les systèmes d’aide à la décision clinique.
Au-delà des applications structurées, l’extraction de NLP est cruciale pour l’entraînement des ensembles de données, l’enrichissement des modèles pré-entraînés et l’amélioration des architectures basées sur l’attention qui sont à l’origine des dernières avancées en matière de NLP.
Aperçu des techniques
Plusieurs techniques sont utilisées pour l’extraction du NLP, allant des systèmes traditionnels basés sur des règles aux modèles d’apprentissage profond.
- Les approches basées sur des règles s’appuient sur des modèles et des règles linguistiques élaborés manuellement pour extraire des informations structurées d’un texte.
- Les modèles basés sur l’apprentissage automatique, en particulier les techniques d’apprentissage supervisé, s’entraînent sur des ensembles de données annotées afin de classer et d’extraire des éléments clés du texte.
- Les techniques d’apprentissage profond, notamment les CNN, les RNN et les modèles basés sur des transformateurs tels que BERT et GPT, extraient des informations clés en analysant les représentations sémantiques et contextuelles des tokens dans une phrase.
- Les grands modèles linguistiques (LLM) améliorent considérablement l’extraction NLP en augmentant la précision et en permettant la création automatique d’ensembles de données pour la formation.
Ces techniques constituent l’épine dorsale des pipelines d’extraction NLP modernes, permettant aux systèmes d’intelligence artificielle de traiter efficacement de grandes quantités d’informations non structurées.
Mythe et réalité
Mythe : l ‘extraction NLP nécessite toujours un apprentissage en profondeur pour être efficace.
Réalité : Les pipelines hybrides combinant des modèles basés sur des règles, des modèles ML classiques et des transformateurs donnent souvent les meilleurs résultats, en particulier dans les applications spécifiques à un domaine. Chez Kairntech, nous permettons une intégration transparente de ces couches afin de maximiser la précision et l’évolutivité.
Techniques de base pour l’extraction NLP
Approches basées sur des règles
Vue d’ensemble et exemples
Les approches basées sur des règles s’appuient sur des modèles linguistiques prédéfinis, des structures syntaxiques et des correspondances de mots-clés pour extraire des informations structurées d’un texte. Ces méthodes fonctionnent en définissant des règles explicites qui reconnaissent les éléments clés d’une phrase ou d’un document.
Prenons l’exemple de la phrase suivante :
« Apple a acquis Beats Electronics en 2014.
Un système basé sur des règles peut définir un modèle tel que :
Si la phrase contient deux entités (par exemple, des noms d’entreprises) et un verbe d’action comme « acquis » ou « acheté », classez-la comme une mention relative à l’acquisition.
En appliquant cette règle, le système extrait :
- Entité 1 : Apple
- Entité 2 : Beats Electronics
- Aperçu contextuel : Événement d’acquisition
⚠️ Attention: Les systèmes basés sur des règles peuvent fournir une grande précision pour des modèles bien définis, mais ils peuvent manquer d’adaptabilité lorsqu’ils traitent des entrées diverses ou non structurées. La plateforme de Kairntech vous permet de combiner des règles avec des ML et LLM – le tout dans un environnement à code bas – pour des pipelines d’extraction plus résilients.
Approches basées sur l’apprentissage automatique
Méthodes supervisées, semi-supervisées et faiblement supervisées
Les techniques d’apprentissage automatique offrent une alternative aux méthodes basées sur des règles en formant des modèles sur des ensembles de données étiquetées afin d’extraire des informations clés. Ces modèles apprennent à reconnaître des modèles dans le texte et à généraliser leurs prédictions à de nouvelles instances.
- Apprentissage supervisé : Nécessite un ensemble de données étiquetées manuellement où chaque élément clé du texte est annoté.
- Apprentissage semi-supervisé : Exploite un petit ensemble d’apprentissage étiqueté et développe les connaissances à l’aide de textes non étiquetés en utilisant des méthodes d’auto-apprentissage ou d’amorçage.
- Apprentissage faiblement supervisé : Il utilise une supervision distante, où des bases de connaissances préexistantes servent de référence pour la formation des modèles.
Techniques d’apprentissage profond
Architectures de réseaux neuronaux (CNN, RNN, transformateurs)
L’apprentissage profond a révolutionné l’extraction NLP en introduisant des modèles neuronaux qui apprennent des représentations textuelles complexes à partir de grands ensembles de données. Les architectures les plus courantes sont les suivantes :
- CNN : Captent les caractéristiques locales d’une phrase, ce qui les rend efficaces pour les extractions à courte portée.
- RNN et LSTM : Traitent le texte de manière séquentielle, en capturant les dépendances à longue distance entre les éléments d’un document.
- Transformateurs : Introduire des mécanismes d’auto-attention, permettant aux modèles d’analyser simultanément des phrases entières et de se concentrer sur les mots clés pour les tâches d’extraction.
Modèles linguistiques pré-entraînés (BERT, GPT, etc.)
Les modèles linguistiques pré-entraînés ont considérablement amélioré les pipelines d’extraction NLP en fournissant des représentations contextuelles des tokens. Au lieu d’entraîner un modèle à partir de zéro, les développeurs peuvent affiner BERT ou GPT sur des ensembles de données spécifiques à un domaine afin d’améliorer l’extraction d’informations.
Le saviez-vous ?
Kairntech vous permet d’affiner les LLM comme BERT ou GPT sur vos ensembles de données internes – sans aucune complexité d’infrastructure. Formez-vous une fois, déployez partout, et obtenez des résultats qui s’alignent sur le vocabulaire et le contexte de votre entreprise.

Applications de l’extraction NLP
Cas d’utilisation dans tous les secteurs d’activité
La puissance de l’extraction NLP va bien au-delà de la recherche universitaire. Elle joue un rôle transformateur dans les industries où l’information structurée est essentielle à la prise de décision.
Biomédical et soins de santé
Dans le domaine biomédical, de grandes quantités de texte – des notes cliniques aux documents de recherche – contiennent des informations précieuses sur les maladies, les traitements et les symptômes. L’extraction NLP automatise l’identification de ces éléments clés, ce qui facilite la découverte de médicaments, les recommandations de diagnostic et l’analyse de la littérature médicale.
Finances et conformité réglementaire
Les institutions financières traitent de nombreux documents – rapports d’activité, dossiers SEC, analyses de marché – dont l’extraction des mentions clés des entreprises, des mouvements du marché ou des mises à jour réglementaires leur confère un avantage concurrentiel.
Recherche juridique et scientifique
Les professionnels du droit et les chercheurs sont confrontés à de vastes collections de documents pour lesquels il est essentiel d’extraire les informations pertinentes des précédents juridiques, de la jurisprudence et des textes réglementaires.

Tirer parti de l’expertise de Kairntech
Pour simplifier l’intégration de l’extraction NLP, les entreprises peuvent se tourner vers des solutions NLP avancées comme celles proposées par Kairntech. Leur pipeline piloté par l’IA automatise l’extraction d’informations à partir de diverses sources textuelles, ce qui facilite la mise en œuvre de modèles pré-entraînés ou leur mise au point sur des ensembles de données spécifiques à un domaine.
Les solutions NLP flexibles de Kairntech aident les entreprises à déployer des modèles d’extraction sans la complexité de la conception, de la formation et de la maintenance d’architectures personnalisées. Leurs outils rationalisent la classification, la reconnaissance d’entités et l’extraction NLP, permettant aux entreprises d’exploiter tout le potentiel de leurs données textuelles.
Cas réel: Une société pharmaceutique internationale a utilisé Kairntech pour extraire les effets indésirables des médicaments à partir de milliers de rapports d’essais cliniques. Le résultat ? Une réduction de 80 % du temps de révision et une plus grande cohérence dans la documentation réglementaire.
Outils et ressources pour l’extraction NLP
Bibliothèques et frameworks populaires
Plusieurs bibliothèques et frameworks open-source offrent des solutions robustes pour l’extraction NLP. Ces outils simplifient la mise en œuvre de modèles de NLP, de la reconnaissance d’entités à l’extraction d’informations structurées, dans divers domaines et cas d’utilisation.
- spaCy: Bibliothèque Python largement utilisée pour le NLP, spaCy fournit des modèles pré-entraînés pour la reconnaissance des entités nommées (NER), l’analyse des dépendances et l’extraction NLP. Elle offre un pipeline facile à utiliser pour l’analyse de texte, y compris des capacités d’entraînement personnalisables qui vous permettent d’affiner les modèles pour les tâches d’extraction de NLP spécifiques à un domaine.
- OpenNRE: Un outil puissant pour l’extraction NLP qui prend en charge une gamme de modèles pour l’extraction d’informations structurées à partir de textes. OpenNRE comprend des modèles pré-entraînés pour diverses tâches de classification, ainsi que la possibilité d’entraîner des modèles personnalisés à l’aide de l’apprentissage supervisé sur des ensembles de données étiquetées.
- AllenNLP: Construit sur PyTorch, AllenNLP fournit une plateforme flexible pour la recherche et le développement de modèles d’extraction NLP basés sur l’apprentissage profond. Grâce à la prise en charge des transformateurs, des mécanismes d’attention et des représentations de jetons avancées, il offre des solutions de pointe pour la classification des textes et l’extraction d’informations.
- Stanford NLP: La suite Stanford NLP offre des modèles robustes pour des tâches telles que la tokenisation, l’analyse des dépendances et l’extraction NLP. Bien qu’elle ne soit pas spécifiquement axée sur l’extraction NLP, elle fournit de solides outils de base pour l’analyse des structures de phrases et l’extraction d’éléments textuels clés qui peuvent ensuite être classés par des modèles d’extraction NLP personnalisés.
Chacune de ces bibliothèques offre une variété de fonctionnalités pour différents besoins, allant d’approches simples basées sur des règles à des modèles avancés d’apprentissage profond, aidant les développeurs et les scientifiques des données à mettre en place rapidement des pipelines d’extraction de NLP pour leurs applications.
Ensembles de données pour l’extraction NLP
La formation de modèles d’extraction de NLP efficaces nécessite des ensembles de données annotés de haute qualité. Vous trouverez ci-dessous quelques ensembles de données clés couramment utilisés pour former et évaluer les modèles d’extraction du NLP :
- SemEval: SemEval est un ensemble de données de référence bien connu pour les tâches d’extraction du NLP. Il fournit des exemples étiquetés d’éléments textuels clés dans de nombreux domaines. Il est souvent utilisé dans la recherche universitaire pour évaluer les performances des modèles.
- FewRel: Cet ensemble de données est conçu pour l’apprentissage en quelques étapes et fournit une collection d’extractions annotées dans divers domaines. FewRel est particulièrement utile pour l’apprentissage de modèles dans des contextes où les données étiquetées sont limitées.
- ACE 2005: L’ensemble de données ACE 2005 comprend un riche ensemble de documents annotés avec des entités extraites et des données structurées dans de nombreux domaines, tels que les fils d’actualité, les nouvelles télévisées et les conversations téléphoniques. Il est couramment utilisé pour former des modèles de reconnaissance d’entités et d’extraction de NLP.
- TACRED: Autre ensemble de données populaire pour l’extraction NLP, TACRED contient des annotations au niveau du document pour les informations extraites dans les articles de presse. Il est souvent utilisé pour entraîner des modèles d’apprentissage profond pour l’analyse de textes structurés.
Ces ensembles de données permettent d’entraîner les modèles à reconnaître et à extraire des informations structurées dans divers textes, améliorant ainsi la précision et l’applicabilité de l’extraction NLP dans des scénarios du monde réel.
Solutions GenAI de Kairntech
Kairntech propose des solutions avancées de GenAI adaptées aux tâches d’extraction du NLP. En intégrant des modèles pré-entraînés de pointe et de grands modèles de langage à des pipelines hautement personnalisables, Kairntech permet aux entreprises de mettre en œuvre des flux de travail d’extraction NLP capables de traiter efficacement des données textuelles à grande échelle.
Les solutions GenAI de Kairntech fournissent :
- Capacités de réglage fin pour les ensembles de données spécifiques à un domaine afin d’améliorer la précision de l’extraction d’informations.
- Annotation automatique des données par des méthodes de supervision à distance et d’apprentissage non supervisé, réduisant les efforts manuels et accélérant le développement de modèles.
- Intégration transparente avec les systèmes NLP existants, permettant aux entreprises de déployer des modèles d’extraction NLP en perturbant le moins possible leurs activités.
Ces outils permettent aux entreprises de tirer parti d’une technologie d’extraction NLP de pointe sans avoir à construire des modèles complexes à partir de zéro. Grâce à l’expertise de Kairntech, les organisations peuvent automatiser la construction de graphes de connaissances, améliorer les processus de prise de décision et renforcer leurs capacités d’analyse de données textuelles.
Liste de contrôle
Avant de choisir votre solution d’extraction PNL, posez-vous la question :
- Ai-je besoin d’un déploiement sur site en raison de la confidentialité des données ?
- Mes équipes manquent-elles de compétences en matière d’IA ? → Envisagez une plateforme à code réduit.
- Est-ce que je travaille avec des documents spécifiques à un domaine ? → Recherchez des modèles pré-entraînés et personnalisables.
- Ai-je besoin de résultats explicables pour assurer la conformité ? → Assurez-vous que l’outil offre des fonctions d’interprétation.
Défis et opportunités
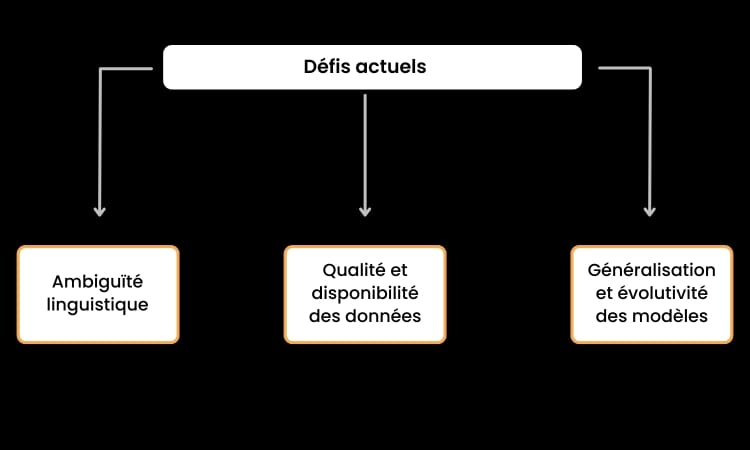
Défis actuels
Bien que l’extraction NLP ait fait des progrès significatifs ces dernières années, il reste plusieurs défis qui affectent la précision, l’extensibilité et l’adaptabilité de ces modèles. Ces obstacles doivent être surmontés afin d’exploiter pleinement le potentiel du NLP dans l’extraction de données structurées significatives à partir de textes.
Ambiguïté linguistique
L’ambiguïté linguistique est l’un des principaux défis de l’extraction NLP. Les entités d’un texte peuvent être exprimées de différentes manières et leur signification contextuelle n’est pas toujours explicite. Par exemple, la phrase :
💡 Conseils d’experts: Pour atténuer l’ambiguïté dans la reconnaissance des entités et l’extraction des relations, superposez vos étapes de traitement: utilisez l’étiquetage de la partie du discours, l’analyse syntaxique des dépendances et le NER spécifique au domaine. Les pipelines modulaires de Kairntech facilitent l’orchestration de ces étapes avec un minimum de code.
« Apple et Microsoft collaborent dans la recherche sur l’IA ».
Les informations extraites de cette phrase dépendent de la capacité du modèle à interpréter correctement le contexte. Comprendre les nuances de la langue est une tâche complexe, et l’entraînement des modèles à gérer une telle ambiguïté est crucial pour une extraction NLP précise.
Qualité et disponibilité des données
Les modèles d’extraction de NLP s’appuient souvent sur de grands ensembles de données pour l’apprentissage, mais l’obtention de données étiquetées de haute qualité peut constituer un goulot d’étranglement. Dans de nombreux domaines, tels que la biomédecine ou la finance, les ensembles de données accessibles au public sont rares et l’annotation manuelle est à la fois longue et coûteuse.
En outre, les textes spécifiques à un domaine comportent souvent une terminologie complexe ou un jargon que les modèles NLP généraux peuvent avoir du mal à traiter. Le défi consiste donc à créer des ensembles de données de haute qualité, pertinents pour le domaine, et à s’assurer que les modèles peuvent s’adapter à ces contextes spécialisés.
Généralisation et évolutivité du modèle
Un autre défi réside dans la capacité des modèles d’extraction du NLP à se généraliser à travers les ensembles de données textuelles. Les modèles formés sur des types de texte spécifiques peuvent ne pas donner de bons résultats lorsqu’ils sont appliqués à des données nouvelles ou inédites. En outre, l’évolutivité peut être un problème, car des ensembles de données plus importants nécessitent des ressources informatiques plus importantes et des modèles plus complexes.
La nécessité d’affiner les modèles pour des tâches spécifiques signifie également que la mise à l’échelle de l’extraction NLP dans différents secteurs ou types de documents peut devenir gourmande en ressources. Pour surmonter ces limites, il faut développer des modèles plus robustes et adaptables, capables de transférer des connaissances d’un domaine à l’autre avec un minimum de recyclage.
Orientations futures
Malgré ces défis, plusieurs opportunités passionnantes promettent de révolutionner l’extraction du NLP et le NLP de manière plus générale. Les progrès de l’apprentissage profond, de l’apprentissage multimodal et de l’IA explicable devraient permettre de s’attaquer à certaines des limites existantes et d’ouvrir de nouvelles possibilités pour l’analyse des données textuelles.
Extraction multimodale du NLP
Les modèles d’IA devenant de plus en plus sophistiqués, ils sont de plus en plus capables de traiter des données provenant de sources multiples, et pas seulement du texte. L’extraction NLP multimodale consiste à intégrer des informations provenant d’images, de vidéos et de textes afin d’extraire des informations structurées sur différents supports.
Extraction NLP explicable
Un autre domaine important de développement est l’extraction NLP explicable. Les modèles à boîte noire, tels que les réseaux neuronaux profonds, sont souvent difficiles à interpréter. Les progrès futurs de l’IA explicable visent à rendre les modèles d’extraction du NLP plus transparents, en fournissant un raisonnement clair derrière les décisions d’extraction.
Apprentissage par transfert et apprentissage à quelques coups
Ces avancées réduiront la nécessité de disposer de grands ensembles de données de formation étiquetées manuellement et rendront l’extraction NLP plus accessible aux petites et moyennes entreprises qui ne disposent pas de grandes quantités de données. Les grands modèles de langage sont une technologie particulièrement puissante pour amorcer l’étiquetage des données.
Chiffre clé
Dans les déploiements d’entreprises utilisant les pipelines NLP de Kairntech améliorés par la génération améliorée de recherche (RAG), les clients ont observé une augmentation de 2× la pertinence des informations extraites de documents longs tels que les manuels techniques ou les textes juridiques.